Lexicon version: …
1.2.3.= Operating system (remove one): Windows / Mac
Windows
Bug description:
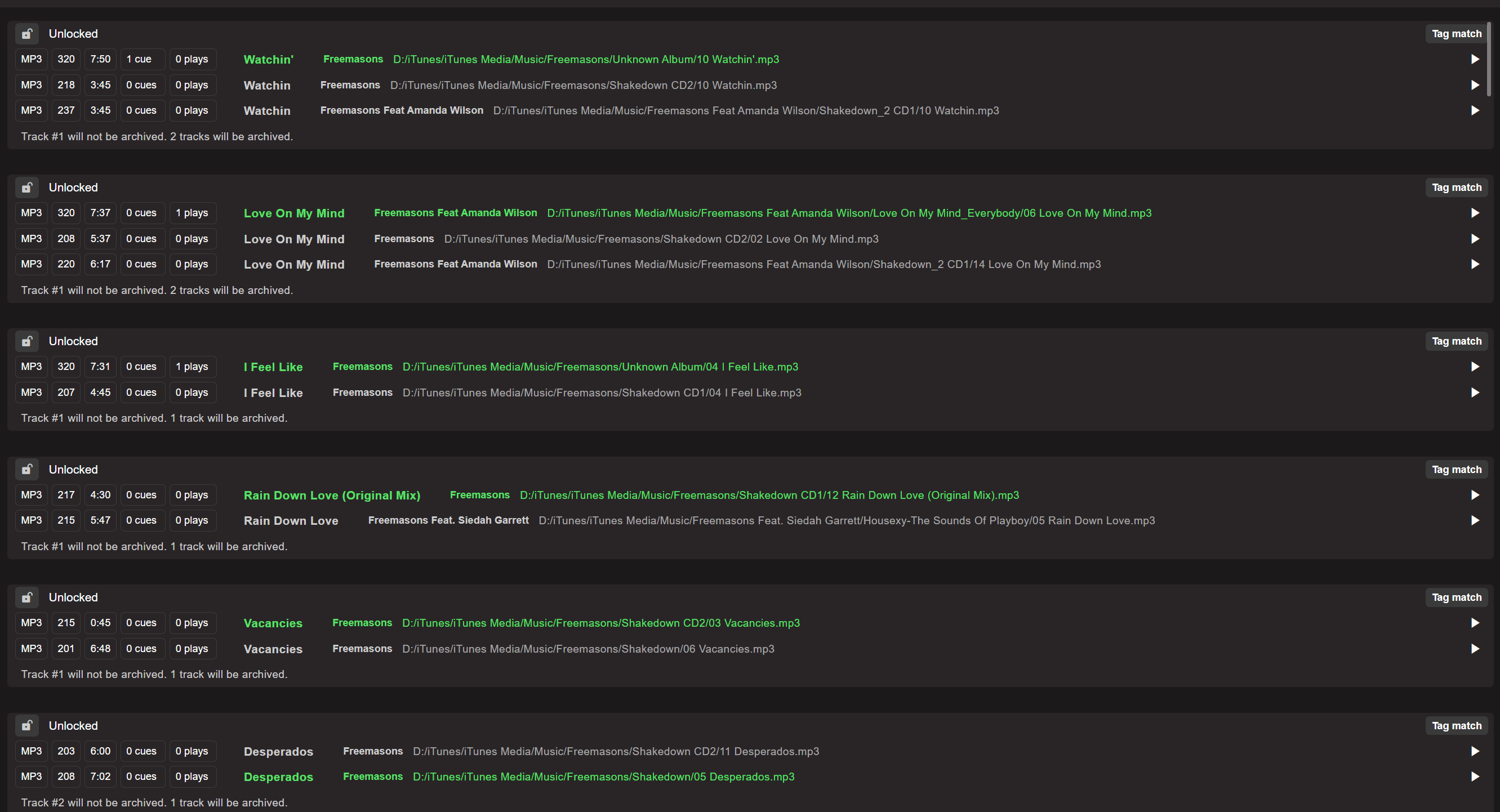
“no false positives” is a bit deceptive and might catch someone out. Maybe the current function listens to part of the track which is, sure, the same, but they’re actually different versions, for example, “remix” by xyz producer and “remix radio edit” by xyz producer.
Perhaps an option to match track length, or even hash the tracks to determine if it’s an exact duplicate.
Step by step to reproduce:
Scan two files that sound the same but have different track lengths, such as remix, and remix radio edit, or full mix (unmixed) and then the same mix, but only part of it mixed into a compilation.
Yeah I think I understand, since you’re getting tag matches. I suppose the guaranteed no false positives only applies to audio matches. The tag matches are very strict on low tolerance and normally that would not result in false positives. But of course, with a tag match the actual audio can be anything. There is an assumption of having tags that are somewhat correct and similar.
I’m still yet to address this issue; I also have so many duplicated files due to relocations, etc.
Perhaps an option to find duplicates the quick & dirty way - based on tag & file info (according to criteria of our choosing) would be a fix both for the false positives issue, and for the missing duplicates issues. I have looked around for the last month or so and haven’t found anything that does it effectively.
Your merge option - where we can choose the cue points, tag info, etc and then replace all instances within playlists etc - is second to none. To do be able to do this with via the tag/filesize/duration criteria of our choosing would be a monumental help - (as many users of Rekordbox will appreciate)!
This would be a way to find duplicates based on properties other than audio fingerprint.
Missing files can’t be fingerprinted but still remain in the library (and some playlists), but are not picked up with the current method. There’s only an option to delete them. Just deleting the missing files would mean they’re gone from playlists without being replaced by the correct file.
Other example would be a Radio Edit, Extended Mix, a version of the extended that is on a mixed compilation CD, and even some Mashups with sections of the original, can turn up as duplicates of the one track (false positive).
Original Mix had corrupt id3 tag, which couldn’t be repaired. It also couldn’t be played in some software. To fix, I re-encoded it with other software and corrupt version was deleted. Corrupt version is throughout many playlists, but audio fingerprint method obviously won’t pick it up. If I delete, it’s also gone from the past playlists I’ve organised it into.
If I could match based on track length, Artist, Track Name, for example, it would see that they’re the same entry, repopulate it in the playlists, and I could opt to also save the play counts to the new file.
Second issue is that I have a copy of the original, and a copy from a compilation CD. Audio fingerprint would pick it up as matching because it sounds the same, although I want to keep them both. It would miss the real duplicate altogether because it can’t scan it.
First up, my apologies, I stand corrected: after scanning a missing file and its replacement with “High Tolerance,” it appears it didn’t use the audio match, as the duplicate remover picked it up. I’d been requesting a function which it seems Lexicon already had:
How can I get all 3 of these Cuff It files into the duplicate scanner result?
Even better, currently (please correct me if I’m wrong) we have to drag/drop into a new playlist, select Utility>Find Duplicates>Only Selected Playlists>High Tolerance>Scan (8 extra clicks) every time we find something new that we deem a duplicate.
What about a function such as right click merge/consolidate, which puts selected tracks at our descretion straight into the “duplicates results” section?
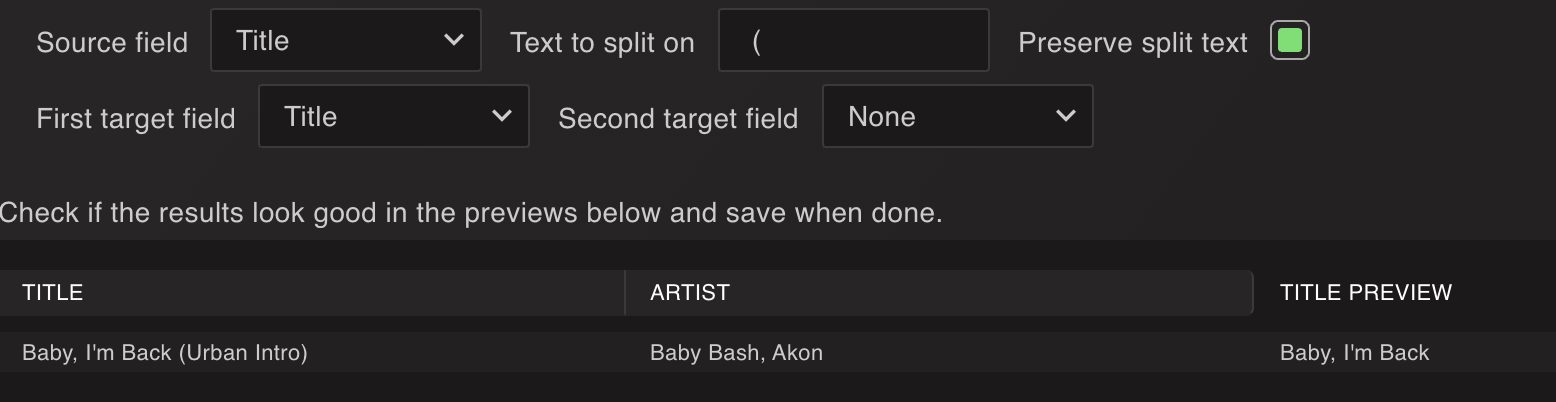
Those titles are too different to be picked up. I would get rid of some of the useless stuff in title. You can use the Split Field recipe (right click tracks → Edit → Recipes) to do that quickly.
Just to be clear, I want to keep Cuff It (TMU Intro Dirty)'s track info/playlist locations.
I want to use the Cuff It (TMU Intro Dirty) (Updated 27) file from now.
I want to delete Cuff It and merge its one or two plays into the keeper.
The first and 3rd are in certain histories and playlists.
That’s an insane amount extra manual work - a fix for a fix. Why not just address the problem? Merge is a ridiculously simple solution that has so many use cases.
It’s disappointing that you deleted a number of my posts. I genuinely don’t want people to go through what I’ve gone through the last couple of months. I’ve sang your praises for years with Rekordcloud/Lexicon.
Sorry I thought that was a duplicate post not related to this topic. It’s still in the other topic, I didn’t delete it there. You can link to that post if you feel that it is relevant here.
Merge is not really simple, there are many things to consider. The duplicate scanner has the ability to merge tracks which is why I’m suggesting to modify your track titles so they show up in there.
I don’t think it’s an insane amount of work. With the Split Field recipe I mentioned earlier, it would clean up things quite fast. Titles don’t need to be the exact same, just turn up the Tag Tolerance option and the duplicate scanner will start to pick them up.